Detekce plagiátorství
V minulém čísle Ikara jsem se zaměřili na obecný popis problémů při detekci plagiátů. Budeme v tomto směru pokračovat, tentokrát však konkrétněji. Uvedeme si příklad metody, která se velmi hezky vyrovnává s problémy, jež jsme minule naznačili.
Možná si vzpomínáte, že jsme hovořili o jakési rybářské síti, s jejíž pomocí se v moři textů lidé snaží padělky ulovit. Ona rybářská síť má různou hustotu ok (tj. dokáže ulovit různě velké ryby), přitom tato oka jsou uvnitř sítě roztroušena různými způsoby - pravidelně, nepravidelně, každé páté oko sítě je menší a tak podobně. Tyto vlastnosti mají přímý dopad na kvalitu systému pro detekci plagiátů, protože ovlivní, kolik vzorků v síti uvázne, a nepřímo ovlivní, jak velký počet ryb bude muset systém srovnávat. Z praktických důvodů není možné lovit každou rybu, a proto se jedná o jakési výběrové šetření.
Velkým problémem je však způsob výběru vzorku. Potřebovali bychom nějakou inteligentní síť - takovou, jejíž oka se roztáhnou, pokud narazí na hejno tuňáků, a naopak se smrští, když síť "nahmatá" přítomnost menších ryb. Ale jak to, ptáme se, může ta síť poznat? Stroj není přece inteligentní, aby dokázal odlišit v textu myšlenky. A i kdyby byl, nehledáme přece výskyty myšlenek, ale výskyty mnohonásobných stejných úseků textu. V okamžiku výlovu nám tedy ještě není známo, zda hledáme tuňáka či makrelu.
Opusťme v tomto bodu metaforu rybářské sítě a podívejme se na jeden, jak doufám, velmi zajímavý a osvětlující pokus. Provedla ho skupina studentů z Cornellovy univerzity nad archivem fyzikálních textů ArXiv [2]. Byl zde použit již známý algoritmus pro detekci sekvencí stejných řetězců (tzv. winnowing) - ovšem v malinko jiném kontextu, než je zvykem. Místo porovnávání řetězců znaků byly vyhledávány výskyty skupin slov. Bylo potvrzeno několik zajímavých věcí:
- Systém pro detekci plagiátů funguje (jistě překvapující zjištění).
- Detekce může proběhnout velmi rychle (zpracování celého archivu, asi 290 tisíc textů, trvalo 20 hodin na jednom stroji Itanium2, 64 bit, 64 GB RAM - v této době není zahrnuto předzpracování textů, tj. konverze a různé vstupní úpravy).
- Je možné porovnávat skupiny slov (místo skupin řetězců), čímž se velmi sníží počet nutných otisků a přitom to nemá negativní dopad na přesnost (my lidé přece jen myslíme ve slovech, a tedy i slova opisujeme) - navíc pokud text rozdělíme na věty a vybíráme z nich skupiny slov, počet otisků se dále dramaticky snižuje.
- Optimální délka m pro skupinu hledaných slov byla experimentálně stanovena na m=7, přitom se zohledňuje okolí slov o délce w=4 (zjednodušeně řečeno: vybírají se kusy textu o délce až 11 slov a z těchto 11 slov je vybrán úsek o velikosti 7 slov a z něj vytvořen otisk).
Samotný algoritmus použitý při testu není nový a byl dokonce před čtyřmi lety patentován [4] (zdá se, že jaksi proti vůli svých tvůrců). Existuje i veřejná služba, která už řadu let pomocí stejného algoritmu porovnává plagiátorství ve zdrojovém kódu programů [3]. Čtenáři najdou matematický popis algoritmu v jiných zdrojích [1], [4], my si zde ukážeme více upovídanou verzi toho, jak systém funguje.
Představme si situaci, kdy máme zpracovat text. Dokument představuje moře kombinací, z něhož je nutno vylovit vzorky:
- Systém text nejdříve rozdělí na věty.
- Pro každou větu bude postupovat (lineárně) od začátku.
- Přitom vybírá vzorky (v našem případě jednotlivá slova) o délce m=7 (sedm slov), vždy se posune o jedno slovo doprava - tak vytvoří množinu otisků (z věty dlouhé 23 slov vytvoří 17 otisků - tj. 13 - m + 1).
- "Lokální winnowing algoritmus" z této množiny otisků vybere několik reprezentativních vzorků. Opět zjednodušeně řečeno: skupinu otisků rozdělí na určité úseky (okna), které se nepřekrývají - z každého úseku pak vybere nejmenší otisk (záleží tedy na kontextu ostatních).
- Vybrané otisky pak systém uloží do indexu spolu s číslem dokumentu (ID); s jejich pomocí bude prováděna detekce.
Příklad výběru otisků:
Z této věty hashovací funkce vytvoří následující skupinu otisků (bod 3, čísla jsou pouze ilustrační):
Při zpracování jiného dokumentu narazíme na následující větu:
Protože algoritmus zvažuje (doslova váží) okolí otisku, tak i toto okolí se promítá do přesnosti detekce. Při výběru z množiny bude algoritmus zkoumat skupinu otisků o délce w=4 a vybrán bude vždy nejmenší ze sousedících (ale nepřekrývajících se) úseků. Tento způsob zaručuje, že budou odhaleny případy plagiátorství, které jsou minimálně 11 slov dlouhé (7 + 4) – přitom kratší úseky textu nemusí, ale mohou být odhaleny (delší úseky textu budou odhaleny zcela jistě) [1].
V případě první věty bude tedy vybrána skupina otisků (17, 8, ..), v případě věty druhé (17, 16...). Tyto otisky budou následně uloženy do indexu a při následném zpracování se zjistí, že otisk 17 se vyskytuje ve dvou textech současně (17 odpovídá textu "ráno a před několika dny jsem zjistil").
Kouzlo podobné detekce spočívá v lokálním charakteru tvorby otisků. Text ovlivňuje jejich výběr a je zaručeno stejné zpracování pro různé dokumenty - nemusíme si lámat hlavu s tím, zda mají být vybírány otisky z každé páté věty, ze začátku dokumentu či náhodně. Pokud se ve dvou různých dokumentech vyskytují stejné věty (a mají délku přesahující jistou hranici), z obou dvou dokumentů bude vybrán stejný vzorek. Takto je velmi velký počet otisků zredukován na opravdu malé číslo, které nicméně stále garantuje detekci stejných řetězců (o délce m+w) [2].
Ostatní závažné problémy
Systémy pro detekci plagiátorství se však musí vyrovnávat s dalšími problémy než jen se způsobem výběru otisků. Pokusím se je naznačit s pomocí následující ilustrace (rukou vyrobené, čímž se omlouvám za kvalitu zpracování - vznikla však při implementaci systému, takže věrně zachycuje strukturu problémů).
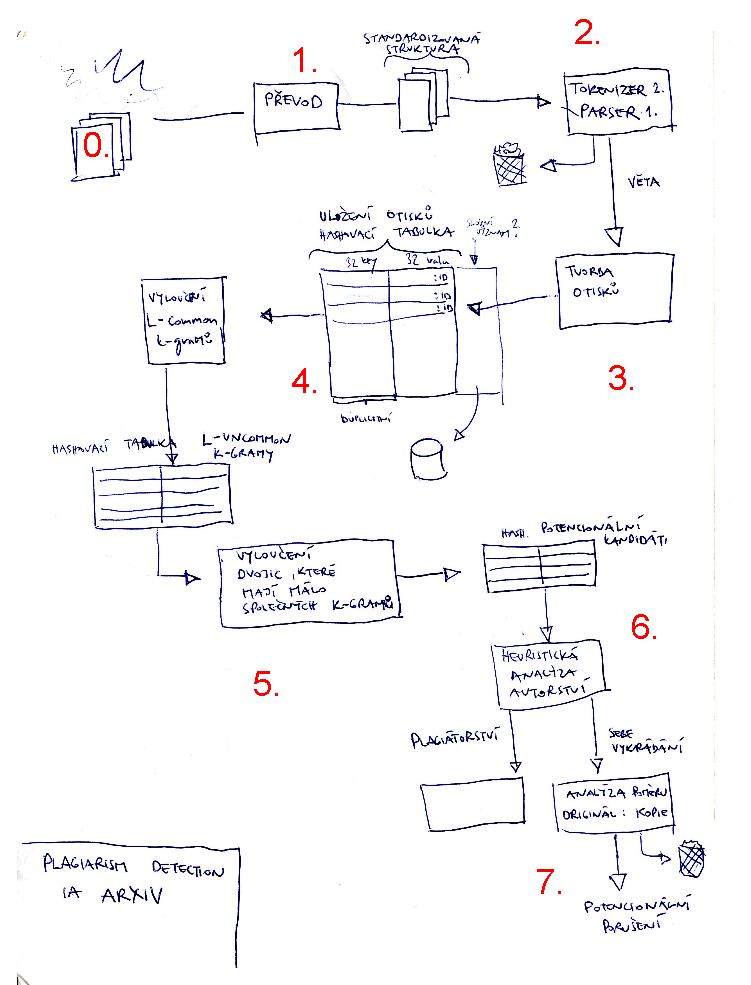
Nákres schématu
- Jádro systémů představuje vlastní tvorba otisků (bod 3).
- Vznikne index otisků, který musí odkazovat na původní dokumenty a také na pozici uvnitř dokumentu, odkud byl daný otisk vybrán (4) - čili musíme minimálně uložit otisk, ID dokumentu a pozici otisku uvnitř dokumentu.
- Ještě než je možné otisky vyrábět, systémy se musí vypořádat s různými formáty souborů, kódováním a převodem do stejné podoby (0, 1, 2) - tyto operace s sebou přináší nemalé těžkosti a může zde docházet k chybám, což snižuje kvalitu detekce. Je například nutné/vhodné ignorovat seznamy citované literatury a zpracovávat pouze tělo textu apod.
- V textech běžně najdeme množství úseků, které se často opakují uvnitř i mezi dokumenty (např. označení instituce, informace o copyrightu apod.). Tyto příliš časté duplikáty je nutno vyloučit. Pokud je zpracováno větší množství dokumentů, tak je tento úkol relativně snadný, budou odstraněny příliš časté výskyty (5).
- Zůstane nám množina potenciálních případů plagiátorství (6).
- Tyto výsledky musí počítač analyzovat (7) a musí to udělat chytře. Je nutno rozlišovat případy, kdy se jedná o citaci (v okolí textu je odkaz na citaci, text je uzavřen do uvozovek), autocitaci (autor cituje sebe sama) či plagiátorství. Jeden dokument může obsahovat úseky vybrané z mnoha jiných textů, či obráceně, jeden původní text může být roztroušen v několika derivátech. V ideálním případě by měl systém určit, kdo vykrádá koho – a to nejsou triviální problémy. K jejich řešení je zapotřebí množství extratextových informací (metadat) o textu samotném - např. jména autorů, datum vydání, zdroj.
Vlastní tvorba otisků (3, 4) se v tomto světle jeví jako poměrně jednoduchý problém, ale už to tak moc neplatí o předvstupním zpracování (body 0-2) a zejména o správném rozpoznávání plagiátů (6, 7). Proto systémy fungují jako pomůcka k vyhledávání podezřelých případů a je nutno, aby lidé výsledky ověřili.
Nicméně, a to by si měli všichni plagiátoři uvědomit, tento a podobné jiné systémy detekce plagiátorství jsou velmi efektivní a vysoce účinné (zaručí odhalení duplicit o jisté délce). Je to zpracování velmi rychlé a pokud připočteme existenci jiných zdrojů (např. bibliografické databáze), pak teprve oceníme potenciál podobných nástrojů jako CrossCheck. To je systém pro detekci plagiátů, jenž využívá dat z dnes největší databáze vědecké článkové produkce CrossRef. Plné texty mají v CrossRef svůj jedinečný identifikátor (DOI) a připojená metadata obsahují důležité strukturované informace o dokumentu. Kromě toho novější záznamy obsahují i seznam citací (referencí) a tím pádem v jejich případě může automatické rozpoznávání pracovati i mnohem lépe a přesněji. Stroj přesněji odhadne, zda určitý případ shody je považován za citaci, autocitaci či vyloženě za případ plagiátorství bez uvedení zdroje.
Jak detekci obejít?
Winnowing je pouze jeden z možných řešení detekce, ale jistě nás napadne, že existuje stále dost prostředků, jak podobné systémy obejít. Jednak změnou převzatého textu, kdy i malé, avšak časté úpravy mohou systémy zmást, jednak změnou pořadí slov, protože zpracování textu je vesměs lineární.
Avšak ani v jednom z těchto případů bych si nebyl jistý. Hashovací funkce se mohou účinně vyrovnat se záměrnými gramatickými chybami, slovníky synonym a terminologie s různými čteními slov a změnám v pořadí by bylo velmi snadné se bránit (přinejmenším s výše popsanou metodou) - stačí před tvorbou otisků všechna slova uvnitř věty srovnat podle abecedy.
Celkem bezpečnou cestou pro "oblbnutí" strojové detekce by (alespoň prozatím) byl překlad do cizího jazyka. Automatický strojový překlad sice může hrát (později) důležitou roli, avšak k detekci plagiátů ho zatím nelze bezpečně použít. Totéž platí i pro detekci založenou na sémantické analýze, tedy rozpoznávání stejného obsahu napříč dokumenty (i když je pravděpodobné, že sémantická analýza může přinést velmi zajímavé výsledky ve spojení se systémy pro detekci plagiátů [3]). Neměli bychom nicméně ale zapomínat na lidskou inteligenci přítomnou ve světě internetu [5], na hodnocení uživatelů, otevřená fóra i roboty, kteří jsou schopni sledovat a hlavně analyzovat citace, nacházet linky a objevovat vazby mezi tím, které zdroje jsou odkazovány a kdy se objevily. Možná že si ještě dnes nedokážeme představit inteligentního agenta, který prochází síťové zdroje a vyhodnocuje citační vazby s cílem najít plagiáty, avšak před dvaceti lety také většina lidí nepočítala s existencí elektronických textů a nástrojů k jejich porovnání. Být plagiátorem, vůbec bych si nebyl jistý, že mohu uniknout nástrojům, které přijdou za pět či deset let. Pokud nemám možnost přepisovat historii (paměť informačních systémů) či nechat texty mizet, vůbec nejbezpečnější by asi bylo nepublikovat vůbec. V opačném případě mi dříve či později hrozí ono skloňované publish and perish.
- Samozřejmě bychom mohli nastavit délku kontextu w nižší, ale v takovém případě se dramaticky zvyšuje množství otisků. Tedy i v případě tohoto algoritmu bylo nutno provést řadu experimentů, při kterých se zjistilo, že w=4 je parametr, při němž je stále odhalena většina případů plagiátorství, i když množství otisků zůstane malé.
- Autoři neuvádějí přesná čísla, ale při zopakování tohoto experimentu nad množinou 90 dokumentů o délce 100 Kb byl průměrný počet otisků připadající na jeden dokument 248. To představuje zhruba 2,5 % objemu testovaného textu.
- Pokud někteří čtenáři znají metodu sémantické analýzy Séman, mohu napovědět, že s její pomocí by podobné srovnávání bylo relativně velmi snadné. Systém Séman text z přirozeného jazyka překládá do znaků univerzálního sémantického kódu, např. věty "šel jsem do školy" a "přišel jsem do školy" by byly přiloženy jako "aabcd ghj0 addi err5" a na podobný výstup by bylo možné použít praktickou stejnou technologii zpracování jako pro detekci plagiátorství.
- SCHLEIMER S.; WILKERSON, D.; AIKEN, A. Winnowing: Local Algorithms for Document Fingerprinting. In Proceedings of the ACM SIGMOD International Conference on Management of Data. June 2003, s. 76–85. Dostupné také na World Wide Web: <http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.6.5709>.
- SOROKINA, Daria, et al. Plagiarism Detection in arXiv [online]. [cit. (2007-09-19]. Dostupný na World Wide Web: <http://www.cs.cornell.edu/~daria/papers/PlagiarismDetection_full.pdf>.
- Moss : A System for Detecting Software Plagiarism [online]. [cit. 2009-28-03]. <http://theory.stanford.edu/~aiken/moss/>.
- The Regents of the University of California. Method and apparatus for indexing document content and content comparison with World Wide Web search service. Inventors: Aiken, A. et al. Int.Cl.: G06F 017/30 . United States Patent, 6 757 675. 2004-29-06.
- Veřejná pomluva plagiátora. ABC Linuxu [online]. [cit. 28-03-2009]. Dostupné na World Wide Web: <http://www.abclinuxu.cz/blog/Robert/2009/2/verejna-pomluva-plagiatora>.