Big Clean 2012
V sobotu 3. listopadu se v prostorách Národní technické knihovny v Praze konala mezinárodní konference Big Clean 2012 s podtitulem "recyklování dat veřejné správy". Hlavním tématem letošního druhého ročníku "velké datové konference" byly otázky, jak vyhledat, zpracovat a analyzovat data nepřesná, nedostupná či nestrukturovaná (např. z mnoha různých webových stránek) a vytvořit z nich data strukturovaná, přehledná a snadno použitelná. Akce tak navázala na úspěšný první ročník z března minulého roku.

Národní technická knihovna
Konferenci zahájil krátkým úvodním příspěvkem Jindřich Mynarz, moderátor konference a jeden z jejích organizátorů. V několika slajdech přiblížil témata, kterým se sobotní akce věnovala, a upozornil na paralelní workshop věnovaný "screen-scrapingu", neboli extrahování dat z různých informačních zdrojů. Zmínku si vysloužil také experimentální catering, o který se postarali nadšení "mrkvaři" z projektu HotKarot a lidé z občanského sdružení Green Doors.


Vlevo: Jindřich Mynarz představuje projekt HotKarot; vpravo: pohled do auditoria Ballingova sálu
Po krátkém úvodu přišla na řadu key-note, kterou si připravil nezávislý nizozemský konzultant Ton Zijlstra. Přístup občanů ke státní správě a státním institucím často probíhá v poměrně konfliktním duchu ve stylu "my" versus "oni". Obě strany spolu nekomunikují (pokud nemusejí), často schází průhlednost a jakékoliv změny přicházejí pomalu. Právě proto je ale důležité tuto situaci změnit – dohlížet na fungování státní správy, mnohem více a lépe komunikovat (a poskytovat zpětnou vazbu) a nejlépe se rovnou i osobně zapojit.
Pan Zijlstra tento přístup ve svém příspěvku ilustroval na řadě příkladů, jako byla například otevřená databáze téměř 50 milionů firem OpenCorporates, švédský projekt CrowdCulture, který kombinuje crowd-funding (peníze od občanů-uživatelů) s veřejným rozpočtem na kulturu, nebo třeba britský PatientOpinion věnovaný hodnocení lékařů a nemocnic (podobně jako náš projekt ZnámýLékař). Účastníky konference také vyzval k zapojení do projektu Wheelmap, který pomocí mapového mashupu hodnotí přístupnost různých budov a lokací pro vozíčkáře.

Projekt PatientOpinion a projekt Wheelmap
Cílem všech těchto aktivit by měl být společný ekosystém státní správy a občanů. Na evropské úrovni se této oblasti věnuje kupříkladu projekt Open Data Portal či platforma EPSI (European Public Sector Information). Ton Zijlstra tedy vidí budoucnost v této oblasti poměrně příznivě a také na nás v závěru svého příspěvku důrazně apeloval, ať jsme "optimistic radical" - optimističtí ohledně toho, čeho můžeme dosáhnout spoluprací s pracovníky veřejné správy a radikální ohledně našeho zapojení a dosažení našich cílů.

Ton Zijlstra účastníky konference vyzval k optimismu, vzájemné spolupráci a odhodlaní něco změnit
Aby výše uvedené projekty mohly fungovat, je třeba získat (zejména od státních orgánů a institucí) data. Ovšem aby byla data skutečně použitelná, většinou je nezbytné je nejprve tak říkajíc "vyčistit", neboli zkontrolovat, ověřit, či opravit. A právě o "čištění dat" hovořila v následujícím příspěvku Jana Chvalkovská z Katedry institucionální ekonomie na Univerzitě Karlově v Praze.
Jana Chvalkovská působí společně s Jiřím Skuhrovcem v projektu zIndex, který hodnotí veřejné zakázky. Databáze, ze kterých projekt čerpá informace (např. Věstník veřejných zakázek) jsou ale velmi často neúplné, ve špatném stavu, bez pořádné struktury nebo obsahují chyby (například v řádech čísel, kde mohou chybět nebo přebývat nuly či desetinné čárky). Čištění dat je tedy velmi důležité pro zajištění důvěryhodnosti projektu i získaných závěrů. Je pochopitelné, že když projekt odhalí nějakou neprůhlednou zakázku či podezřelý tendr, takto označené firmy se intenzivně brání.

Jana Chvalkovská představuje projekt zIndex
Jako příklad J. Chvalkovská uvedla kauzu IKEM & Kardioport, které se věnovaly i Hospodářské noviny. Po opakované medializaci podezřelé zakázky za stovky milionů korun začala ředitele IKEMu Jana Malého spolu s jeho náměstkem Ivanem Netukou vyšetřovat protikorupční policie, a oba byli ze svých funkcí odvoláni. Jiří Skuhrovec je vedle zIndexu také autorem projektu VášMajetek, který funguje jako centrální databáze dražeb, aukcí a prodejů státního majetku, majetku měst, obcí a krajů a exekučně zabaveného majetku.
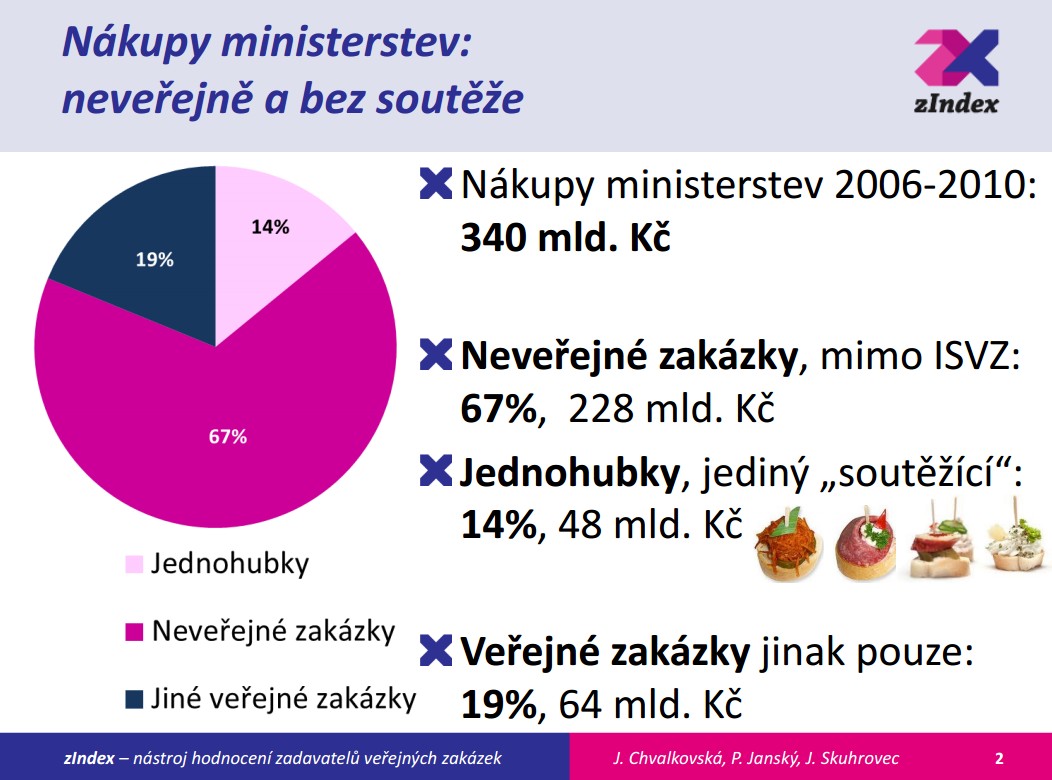
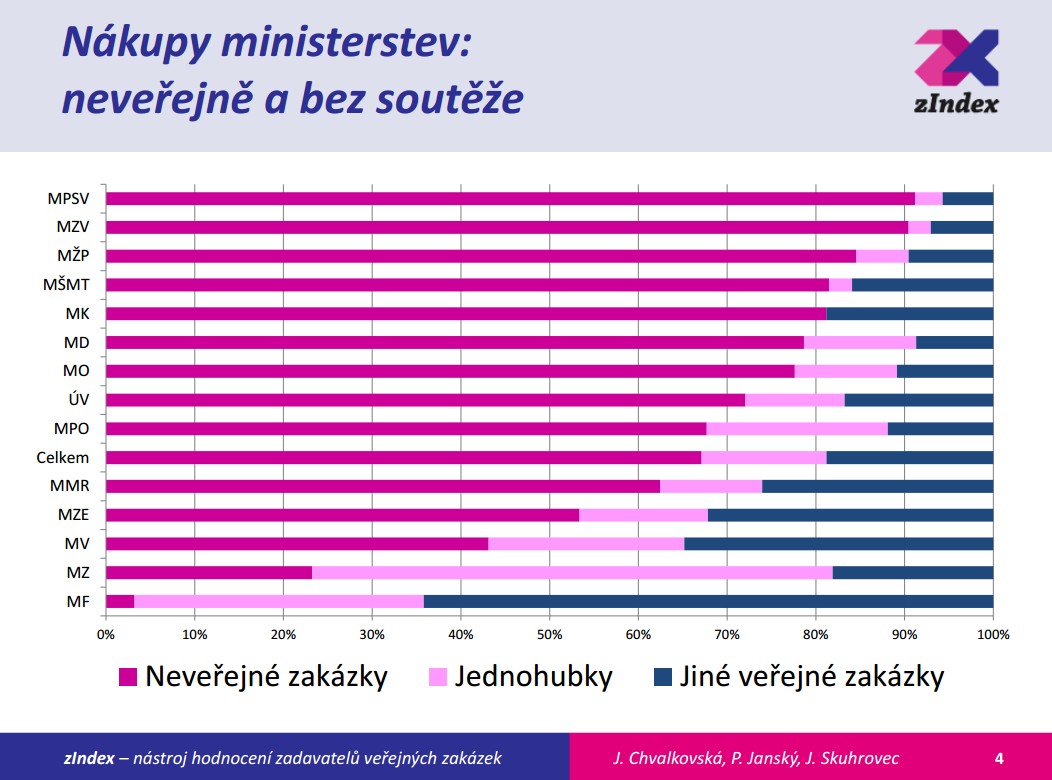
Vybrané statistiky veřejných zakázek z projektu zIndex (zdroj: prezentace zIndexu)
V následující prezentaci vystoupil Jan Michelfeit z Matematicko-fyzikální fakulty UK, který představil projekt ODCleanStore (Open Data Clean Store). Cílem projektu je vytvořit infrastrukturu věnovanou zpracování, ukládání a publikování dat. Podobně jako v případě zIndexu a dalších projektů je i zde velmi důležité čištění dat, která jsou díky "data-miningu" z různých zdrojů často chybná, neúplná nebo naopak duplicitní. Orientaci alespoň částečně napomáhá automatické hodnocení kvality či důvěryhodnosti, ale i zde je potřeba informace manuálně kontrolovat.
Jan Michelfeit ve svém příspěvku představil také projekt OpenData, neboli iniciativu za transparentní a otevřenou datovou infrastrukturu. Na přípravě tzv. "katalogu dat" i samotné infrastruktury pracují především studenti Matematicko-fyzikální fakulty UK a Fakulty informatiky a statistiky VŠE.

Jan Michelfeit hovoří o řešení konfliktů v rámci softwaru ODCleanStore
V tématu sbírání a zpřístupňování dat pokračoval i Friedrich Lindenberg, programátor a vývojář Open Knowledge Foundation. Podobně jako key-note speaker Ton Zijlstra si ve své prezentaci připravil celou řadu zajímavých příkladů, které shromažďují a zpřístupňují data nejen na lokální, ale i na celoevropské úrovni. Za zmínku stojí kupříkladu projekt FarmSubsidy.org věnovaný farmám a zemědělcům, kteří ročně dostávají od Evropské unie příspěvky ve výši 55 miliard Eur. Za povšimnutí také stojí projekt časopisu Financial Times zaměřený na financování z evropských strukturálních fondů.
Mezi významné projekty nepochybně patří i data.gov.uk s podtitulem "Opening up Government". Jedná se o jednotnou databázi více než osmi tisíc dílčích dat, tabulek a databází ze všech možných "koutů" Velké Británie. Informace z ministerstev, vládních institucí a dalších součástí veřejné správy jsou tak rychle a jednoduše přístupné a vyhledatelné z jednoho místa, z jednoho portálu. V závěru pan Lindenberg zmínil také českou Mapu projektů zaměřenou na projekty spolufinancované z evropských fondů v České republice. V databázi projektu jich je zatím více než 11.000.

Friedrich Lindenberg ve své prezentaci zmínil i český projekt věnovaný evropským fondům
Poslední přednášku dopolední sekce konference Big Clean si připravil Filip Hráček z české pobočky společnosti Google. Svůj příspěvek zahájil krátkým výčtem důvodů, proč je obtížné pracovat s tzv. "velkými daty" (anglicky "big data"). V zásadě platí, že u velkých dat je složité a komplikované úplně všechno. Obtížný je jejich sběr, obtížné je jejich čištění, velmi obtížná je jejich analýza, a obtížné je i jejich sdílení. Velká data jsou totiž skutečně velká – pod tímto označením si můžeme představit tabulky či databáze, které mají třeba desítky milionů řádků dat a jejichž velikost se počítá na jednotky ale i desítky GB.
Jen málokterá společnost má tolik zkušeností s velkými objemy dat, jako právě Google. Není tedy divu, že nám Filip Hráček představil celou řadu zajímavých nástrojů, které si dokáží poradit i s daty, se kterými by bylo obtížné či zcela nemožné pracovat jen lokálně na počítači. Na sdílení velkých objemů dat lze kupříkladu použít nástroj Google Fusion Tables, pro sledování trendů a jejich vzájemné porovnávání je určena dvojice nástrojů Google Trends a Google Trends Correlate, a pro již zmiňované čištění dat je k dispozici program Google Refine.
Portfolio představených nástrojů a aplikací uzavřela výkonný cloudový nástroj Google BigQuery, určený pro analýzu velkých dat. Nástroj jsme si vyzkoušeli i v praxi na obrovské tabulce obsahující všechny narozené děti v USA od roku 1969 do roku 2008. Tabulka měla velikost 22 GB a obsahovala přes 137 milionů řádků – pro každé dítě jeden. Rozdíl ve výkonu byl mimořádný – zatímco jen prosté spočítání celkového počtu řádků na výkonném počítači trvalo několik minut, v rámci služby BigQuery to byla otázka přibližně tří vteřin. Klíčem k tomuto výkonu je samotná infrastruktura Googlu, kterou tvoří stovky tisíc serverů a výkonných počítačů – a proto jich může na složitém dotazu pracovat třeba několik set současně. Po několika vteřinách "přemýšlení" jsme se kupříkladu dozvěděli, že se v USA za necelých 40 let narodilo více než 456 tisíc tun dětí. :)


Filip Hráček hovoří o velkých datech
Polední přestávka konference Big Clean patřila již v úvodu zmiňovanému "experimentálnímu cateringu". Vedle klasického občerstvení byl účastníkům k dispozici i stánek s mrkví v rohlíku od skupiny HotKarot. Její členové si navíc připravili i konferenční specialitu – interaktivní omáčku s názvem Eat your Tweet. Celá konference totiž využívala sociální média, především pak Twitter, a sledovala příspěvky účastníků doplněné hash-tagem #bigcleancz. Výsledná omáčka pak vznikla na základě textové analýzy Twitteru. "Četnost a blízkost slov nám udá souřadnice barevného spektra, které se spárují v OpenSauce s vybranými ingrediencemi", vysvětlují tvůrci na stránkách projektu.



Stánek HotKarot se připravuje na polední přestávku


Klasický i experimentální catering v plném proudu
Odpolední část konference odstartovala čtveřicí krátkých tematických prezentací nazvaných Lightning talks. Prvním řečníkem tohoto pásma byl Jan Cibulka, který představil svůj projekt mapující pražskou kriminalitu. Údaje z policejních statistik násilné a majetkové kriminality za rok 2011 vizualizoval do mapy Prahy až na úroveň ulic, resp. na úroveň jednotlivých policejních služeben. Porovnáním počtu trestných činů a počtu obyvatel v okolí konkrétních služeben pak bylo možné vypočítat relativní míru kriminality a ilustrovat ji sytostí červené barvy.

Vlevo: Jindřich Mynarz a Jan Cibulka; vpravo: ukázka z projektu "Mapy Kriminality"
V následujícím "bleskovém příspěvku" nám Peter Zvirinský představil nástroj Strigil, který můžeme označit jako "web scraping tool", neboli nástroj pro extrahování dat z webových stránek. Přednášející se po krátké ukázce (sklízení dat z databáze veřejných zakázek) věnoval také samotné architektuře nástroje. Zmínil, že Strigil lze propojit s Excelem a může být napojen na datové úložiště ODCleanStore, o kterém v dopolední sekci hovořil Jan Michelfeit.
Friedrich Lindenberg přiblížil účastníkům řadu zajímavých datově-orientovaných projektů již v dopolední sekci. Tentokrát se ale zaměřil na finance a představil projekt WhereDoesMyMoneyGo? spočívající v analýze a vizualizaci využití peněz z daní ve Velké Británii. Uživatelé mohou jednoduše uvést svůj příjem a ihned zjistí, kolik peněz z jejich daní jde na vzdělání, kulturu, obranu atd. Na základě toho anglického projektu pak vznikl rozsáhlý mezinárodní projekt OpenSpending, který v současné době obsahuje více než 120 různých "rozpočtů" ze 40 zemí světa.


Peter Zvirinský a Friedrich Lindenberg
Posledním speakerem tohoto pásma byl estonský rodák Henri Laupmaa, který představil analytický a vizualizační nástroj Community Tools. Jeho vývoj byl inspirován projekty typu Ushahidi nebo SeeClickFix; a v zásadě se tedy jedná o využití nových technologií ke sdílení problémů a jejich řešení. Aplikace má obvykle podobu mapy, do které mohou uživatelé vkládat konkrétní problémy (někde něco chybí nebo nefunguje), které pak mohou jiní uživatelé (nebo veřejná správa) řešit.
Henri Laupmaa zůstal u pomyslného řečnického pultu i po skončení série Lightning talks. Vystoupil totiž s ještě s příspěvkem zaměřeným na praktické ukázky (případové studie) práce s daty a jejich vizualizace. Z mezinárodních projektů zmínil kupříkladu portál ProtectedPlanet, který mapuje národní parky a chráněné krajinné oblasti po celé Zemi. Většina příkladů se ale týkala Estonska – například projekt "digitální občanky" Digital ID, informační portál eesti.ee s podtitulem "Gateway to Estonia", či projekt SmartVote, který sleduje názory poslanců estonského parlamentu.

Henri Laupmaa představil nástroj Community Tools a několik estonských projektů
Neustále stoupající množství dat z více či méně dostupných zdrojů umožnilo i vznik nového odvětví žurnalistiky – tzv. "datovou žurnalistiku" (anglicky "data journalism" či "data-driven journalism"), kterou na konferenci představila Liliana Bounegru z European Journalism Centre. Takový přístup k novinářské práci je sice náročnější a vyžaduje často nelehké vyhledávání a ověřování získaných dat (nebo přímo i generování dat vlastních), ale výsledkem jsou kvalitní články a informační zdroje, které se mohou opřít o ověřená a relevantní data, které obsahují vypovídající statistiky a vizualizace, a které jsou v konečném důsledku pro čtenáře mnohem přínosnější, než opisování tiskových zpráv a novinek z tiskových kanceláří.
Datová žurnalistika také ovlivňuje a redefinuje i samotné novinářské prostředí. Mnoho informací, dat, novinek a námětů nepřichází jen od "novinářů z povolání", ale od obyčejných lidí po celé zemi nebo po celém světě. Díky Internetu a sociálním sítím se může zapojit doslova každý – poukázat na problém, poslat svůj příběh, sdílet fotku nějaké události, upozornit na nějaký zdroj informací atd. Úkolem novinářů je pak tyto informace ověřit, vyhodnotit, zpracovat a publikovat.
Liliana Bounegru také představila portál Data Driven Journalism, který obsahuje informační zdroje, návody a případové studie věnované právě datové žurnalistice. Výsledkem spolupráce mnoha odborníků je také obsáhlá příručka Data Journalism Handbook, která vznikla za podpory European Journalism Centre a Open Knowledge Foundation. Publikace se věnuje všem důležitým tématům datové žurnalistiky – tj. jak získat, data, jak jim porozumět i jak je nejlépe využít – a opět nabízí i bohatou přehlídku zajímavých případových studií. Publikace je k dispozici jak k zakoupení v nakladatelství O'Reilly, tak i ve formě volně přístupné webové verze.


Liliana Bounegru se věnovala tématu datové žurnalistiky a představila publikaci Data Journalism Handbook
V posledním příspěvku sobotní konference navázala novinářka Caelainn Barr z UK na téma datové žurnalistiky a zaměřila se na využití dat z Evropské unie. EU pochopitelně nabízí obrovské množství dat, která jsou důležitá pro občany i novináře, ať už na regionální, národní či celoevropské úrovni, ale ke kterým je jako obvykle často poměrně obtížné se dostat (resp. vypátrat je ze všech zdrojů, webů, jazykových verzí a podstránek), a ještě obtížnější je jejich čištění a zpracování.
V tomto kontextu přednášející představila rozsáhlý projekt věnovaný strukturálním fondům EU. Zpracování a čištění obrovského objemu dat bylo mimořádně náročné a zabralo přibližně devět měsíců práce. Ačkoliv byla data vždy "oficiálně" někde dostupná (zejména díky legislativě o volném přístupu k informacím), každá instituce a každá země je prezentovala odlišným způsobem. C. Barr zmínila, že jedním z nejlepších příkladů bylo Slovensko, zatímco nejhorší situace byla asi v Rumunsku, kde byla spousta informací pouze "off-line", např. na fotokopiích. Překvapivě uzavřené bylo i Německo, které mělo řadu informací v uzamčených (nepřístupných) .pdf.
Několikaměsíční snaha získat potřebné informace tak připomínala "kobercové bombardování", kdy autoři projektu rozesílali desítky a stovky dotazů denně na všechny strany, na všechny úřady, subjekty a instituce. Další měsíce práce pak zabralo jejich ověřování, vyhodnocení a vzájemné porovnání. Ačkoliv si projekt vyžádal mnoho času a úsilí, výsledkem byl unikátní přehled financování ze zdrojů EU, série článků v mnoha exponovaných médiích a mimo jiné i již zmiňovaná databáze evropských strukturálních fondů v časopisu Financial Times.


Caelainn Barr se zaměřila na strukturální fondy EU a výsledný projekt na stránkách Financial Times
Souběžně s hlavní přednáškovou částí konference probíhal většinu dne také workshop zaměřený na získávání dat od veřejných institucí. Lektor Thomas Levine (vybavený kromě obligátního notebooku také fixou a blokem papíru) pohovořil o spolupráci s armádou a dalšími institucemi, a obecně o (ne)ochotě veřejně sdílet data např. z rozhodování o územním plánování. Zmínil také problémy, které výměnu dat komplikují – např. když instituce sice data poskytne, ale v naskenovaných souborech ve formátu *.pdf. Následně účastníkům workshopu předvedl, jak se s některými potížemi vyrovnat.
Thomas Levine také v praxi demonstroval již zmiňovanou techniku "scrapingu", se kterou se dají extrahovat data z veřejně dostupných webových stránek. Ze stránek amerického ministerstva práce například zjistil, kolik pracovníků je sdruženo v odborových organizacích nebo u kolika projektů vyprší doba podání žádostí k dnešnímu dni – a to vše pouhým přepisováním krátkého kódu ve volně dostupné aplikaci ScraperWiki.



Thomas Levine a účastníci celodenního workshopu
Posledním bodem konference Big Clean 2012 byl diskusní panel "Ask anything session", kterého se zúčastnila většina přednášejících: Ton Zijlstra, Friedrich Lindenberg, Liliana Bounegru, Caelainn Barr a Thomas Levine. Ti společně shrnuli základní témata konference a odpověděli na otázky, které jim návštěvníci položili buď osobně nebo přes Twitter (a již zmiňovaný hash-tag #bigcleancz). Poté již následovalo jen poděkování, rozloučení a pozvánka na Big Clean v roce 2013.



Závěrečná diskuse, poděkování účastníkům & neformální večerní networking v nedaleké restauraci