Projekt Dáme práci
Růst informací a způsoby jejich zpracování
V posledních dvaceti letech jsme v oblasti zpracování informací (a to nejen na internetu) svědky prudkého a často překotného růstu jejich objemu. Informace jsou navíc určeny pro stále větší počet příjemců. Tento růst je dán především technickým a ekonomickým “snížením prahu” nutného k publikaci informace v různém mediálním prostředí. Nejdrastičtější nárůst v tomto kontextu vidíme především v oblasti WWW, kde technologická epocha označovaná jako Web 2.0 proměnila de facto všechny účastníky komunikace na webu v producenty, a zásadně tak zvětšila objem dostupných informací.
Souběžně s tímto procesem se rozvíjejí i techniky zpracování informací, a to dvěma zásadními směry. Prvním jsou přístupy spojené s tradicí statistického zpracování dat (řadíme sem i nejrůznější formy data miningu, strojové učení atd.). Druhým přístupem jsou potom techniky spojené s využíváním lidmi vytvořených ontologií, které jsou aplikovány do prostředí internetu polo-automaticky. Tento směr především ústí do oblasti nazývané sémantický web a má, genealogicky vzato, nejblíže k informačním studiím a knihovnictví.
Tyto dva přístupy se neliší jen v metodologické rovině, ale také ve svém prvotním účelu. Statistické metody jsou určeny de facto k preprocessingu informací a nezajímají se často o význam informace (kupříkladu pojmenování topics nalezených pomocí techniky LDA není nutné pro jejich využití během dalšího zpracování). Oproti tomu sémantické techniky se především orientují na přímé využití sémantické znalosti vnořené kupříkladu do mikroformátu pro zpracování strojem. Zjednodušeně řečeno se statistické metody snaží vyextrahovat vzorce z chování systémů (ať už jimi jsou texty nebo lidské jednání) a jsou v tomhle ohledu orientovány na pragmatiku. Jejich výstupy se nesnaží ale napodobit lidské chápání. Oproti tomu sémantické technologie se snaží v podstatě aplikovat znalosti o lidské sémantice na strojově zpracovatelnou oblast.
Oba přístupy mají své meze, které snad nejjednodušeji shrnul Peter Norvig jako problém ceny versus velikosti doménové oblasti[1], v níž má být daná technologie aplikována. Pro malé a přesně ohraničené znalostní oblasti, jako například datová reprezentace fyzické adresy, je snadné a levné vytvořit datovou specifikaci pro její popis, avšak pro oblast nestrukturovaných dat z webových stránek je vytváření podobných systému nejen drahé, ale prakticky nemožné, protože stoupá komplexita a množství daných domén.
Běžný uživatel webu se samozřejmě přímo nesetkává ani s jednou z technologií, přesto ale mají na jeho pohyb v tomto prostředí velký vliv. Rozhodují totiž o snadnosti dohledatelnosti informací, které uživatel na webu publikuje.
Příklady
Výsledky zpracování dat pomocí statistických metod může producent informací ovlivnit jen velmi málo, byť i toto málo stojí za celou jednou obchodní oblastí na internetu nazývanou Search Engine Optimization. Lépe je na tom tvůrce obsahu v oblasti sémantického zpracování: zde sice nemůže přímo ovlivnit pořadí výsledků ve vyhledávačích, ale může ovlivnit podobu zobrazení a kvalitu zpracování. Cestou k tomu je využití různých forem sémantických mikroformátů a mikrodat, které dnes vyhledávače (ale také sociální sítě jako Facebook) podporují.
Jednoduchým a nejklasičtějším příkladem je zmiňované uvedení adresy kupříkladu sídla firmy. Na webové stránce potřebujeme uvést následující adresu:
Studia nových médií FF UK
U kříže 8, Praha 5 - Jinonice
15800 Prague, Czech Republic
V jednoduché podobě bude v HTML vypadat nějak takhle:
<h3>Studia nových médií FF UK</h3 >
<p class="adresa">
Studia nových médií FF UK<br>
U kříže 8, Praha 5 - Jinonice<br>
15800 Prague, Czech Republic<br>
</p>
Stroj, který přijde na stránku, však nebude vědět vůbec nic o tom, o jaký obsah se jedná. Pomoci mu můžete, pokud využijete například mikroformát hCard. Stačí zápis jen mírně upravit:
<div class="vcard">
<div class="fn org">Studia nových médií FF UK</div>
<div class="adr">
<div class="street-address">U kříže 8</div>
<span class="locality">Praha 5 - Jinonice</span>
<span class="country-name">Czech Republic</span>
</div>
</div>
Podoba zobrazení na stránce zůstává z pohledu uživatele stejná, radikálně se ale mění možnosti strojového zpracování. Na obrázku můžete kupříkladu vidět, jak vypadá zobrazení receptu na jídlo na Googlu v případě, že byl recept označen pomocí sémantických značek pro hodnocení kvality, a jak v případě nesémantického formátování.

Recept zapsaný s využítím sémantických značek

Recept bez sémantických značek
Na konci příkladu je třeba zdůraznit ještě jeden důležitý aspekt používání sémantických značek: webové stránky se díky nim stávají přístupnější pro širší zpracování než jen pomocí vyhledávačů.
Internetové služby zprostředkovávající práci
Domácí ekonomika se již řadu let potýká s problémem vysoké nezaměstnanosti. Nezaměstnanost sama o sobě je komplexní problém, který nemá jednoduché řešení. Přesto lze ale pro její snížení učinit určitá opatření, která mají v podstatě povahu strukturální. Patří mezi ně i urychlení šíření informací o volných místech. Svou roli hraji vylepšení výsledků s nabídkou práce o inzeráty, nabízející práci podobnou. Specifický případ tvoří aplikace rozšiřující možnost lépe zpracovávat informace od potenciálních zaměstnanců a poskytovatelů práce. Tyto aplikace však, pro svou vysokou specializaci, nejsou předmětem obecného zájmu.
Na tyto požadavky vždy reagovaly agentury zprostředkovávající práci a to dlouhou dobu před nástupem internetu. Ačkoli internet přinesl novou dynamiku do jejich činnosti, samotný obchodní model se příliš nezměnil. Agentury stále pracují nejčastěji s mírou exkluzivity informací, které mají k dispozici (a s nimi spojenými provizemi za nalezení zaměstnance). Dále pak nabízejí systémy, které usnadňují práci s informacemi o nabídce a poptávce (dnes řada z nich tvoří vlastně outsourcing HR). Konečně pak mají příjmy spojené s dalšími činnostmi vázanými na specifické skupiny jako jsou nejrůznější školení a rekvalifikace uchazečů.
„Dáme práci“ jako aplikace principů sémantického webu
Obchodní modely komerčních subjektů na trhu s sebou přinášejí vždy určitá omezení. Nejčastěji v podobě exkluzivity pro jediný subjekt či vyšších transakčních nákladů pro zadání inzerce. Tato omezení mají své důvody, v konečném důsledku ale přinášejí zpomalení toku informací na trhu práce.
V tomto ohledu nám na Studiiích nových médi přišlo užitečné přispět technologickým řešením postaveným na principech sémantického webu, které by využívalo právě jeho hlavní výhody: jednoduchost implementace a snadnost zpracování na straně poskytovatele informací (a zaměstnání), a zároveň poskytovalo nekomerční platformu, která by se vyhnula problémům, jež generují tradiční agenturní řešení. Tedy zejména uzavření dat. Naším cílem není (a nebylo) konkurovat komerčním subjektům, ale naopak vstoupit do míst, která nejsou pro většinu z nich lukrativní.
Tak vznikl projekt Dáme práci, který je realizován v rámci OPLZZ. Jeho plný název zní Využití mezinárodních zkušeností s business ontologiemi pro návrh a vývoj platformy propojení nezaměstnaných s poskytovateli přímých nabídek práce prostřednictvím hyperlokálních služeb. Řešitelem projektu se stala Univerzita Karlova prostřednictvím pracoviště Studia nových médií na FF UK.
Cílovou skupinou projektu Dáme práci jsou jak ohrožené skupiny, tak zaměstnavatelé: pro ohrožené skupiny (absolventi, matky a otcové po rodičovské dovolené, lidé starší 50 let) je určena výsledná aplikace DámePráci.cz. Jádrem našeho projektu je návrh a vývoj platformy propojení nezaměstnaných s poskytovali přímých nabídek práce prostřednictvím hyperlokálních služeb. V praxi jde o vytvoření nejen specifikace mikrodat použitelných pro webové nabídky práce, ale také o přenesení způsobů jak takové specifikace vytvářet a navržení a vytvoření softwarové infrastrukury pro ni. Webová služba www.damepraci.cz pak demonstruje možnosti, které platforma nabízí.
Jak už z názvu vyplývá, v projektu nám nešlo jen o specifické řešení pro trh práce, ale také o využití mezinárodních zkušeností s business ontologiemi a transfer znalostí z této oblasti do České republiky (mj. i prostřednictvím dvou mezinárodních konferencí na toto téma, na nichž se podíleli kolegové z partnerských univerzit v irské Galwayi a nizozemském Tilburgu, kteří pomohli přenést zkušenosti s využíváním sémantických technologií do České republiky). Zaměstnavatelé tak získávají nejen infrastrukturu využívající principy sémantického webu pro efektivnější způsob nabízení práce, ale také informace o tom, jak v budoucnu prakticky postupovat při využívání business ontologií i v jiných oblastech.
Mikrodata a datový model
Postup analýzy dat a vznik datového modelu
Projekt sám byl vítanou přiležitostí si vyzkoušet v praxi i několik základních postupů při tvorbě ontologií pro sémantické projekty. Po konzultacích s partnery v Irsku a Nizozemsku jsme začali nejprve rozhovory s doménovými experty. Byli mezi nimi jak nezaměstnaní, tak odborní garanti projektu z Katedry sociální práce na FF UK, stejně jako zástupci zaměstnavatelů.
Z rozhovorů jsme nejdříve extrahovali často se opakující struktury v požadavcích potenciálních zaměstnavatelů, stejně jako uchazečů o práci. Zvláštní pozornost jsme věnovali otázce priorit při popisu zaměstnance, popisu práce i při rozhodování se o nabídce práce.
Dalším krokem byla konfrontace informací získaných od doménových expertů s daty z nabídek práce samotných. Zvolili jsme dataset s více než 1000 inzerátů z Craigslistu (abychom mohli práci dál průběžně konzultovat se zahraničními partnery). V analýze jsme postupovali jak kvalitativní metodou, tak kvantitativní.
Při kvalitativní části jsme ručně tagovali inzeráty podle přítomnosti atributů jako je plat, typ úvazků, vzdělání a podobně. Pro kvantitativní část jsme si vytvořili jednoduchý nástroj nazvaný Corpus Viewer, který kvantifikoval souvýskyt slov, a umožnil tak exaktně potvrdit některé hypotézy (aplikaci si můžete sami vyzkoušet) nad českými daty.
Výsledkem této části byl seznam atributů (např. datum nástupu, telefon do organizace apod.), který sice dobře pokrýval nabídku i poptávku práce, ale na kterém jich bylo více než osmdesát, a tím pádem byl prakticky nepoužitelný. Nastala proto fáze redukování datového modelu na přijatelné minimum. Jeho schéma je znázorněno na následujícím obrázku:
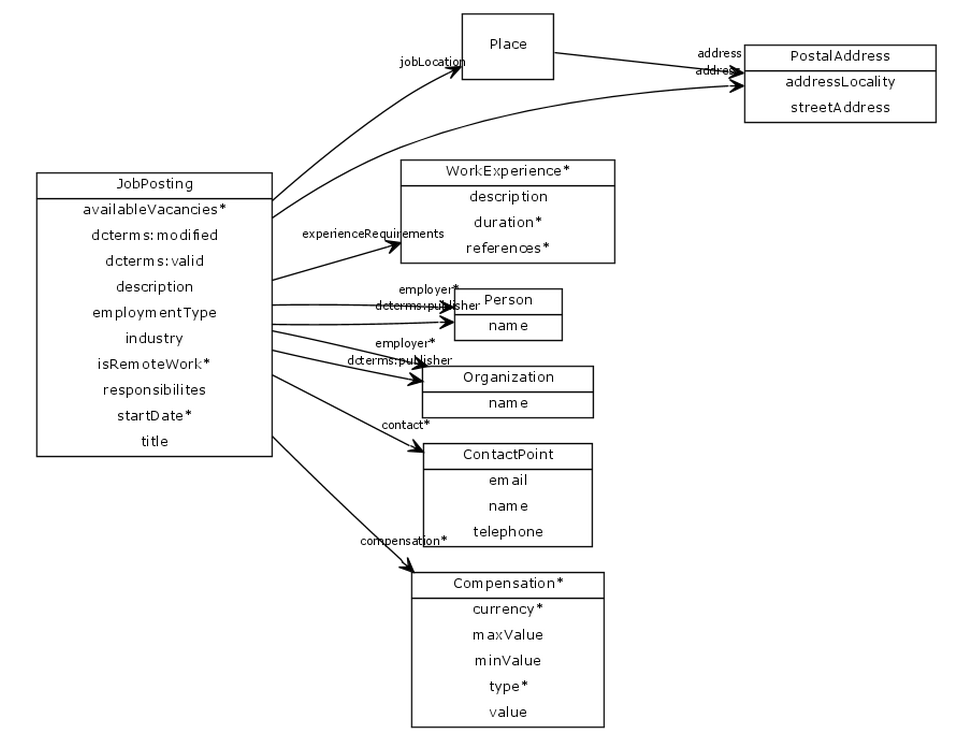
Schéma datového modelu projektu DamePraci.cz
Specifikace mikrodat a jejich ukázka
S finálním datovým modelem nastal problém: jakou cestou se vydat pro specifikaci mikrodat. Na jednu stranu bylo možné vytvořit zcela nové značky, které by přesně vyhovovaly potřebám našeho projektu – tím bychom ale prudce snížili jejich šanci na uplatnění. Anebo jsme mohli využít pro popis kombinaci stávajících značek, které jsou podporovány světovými vyhledávači a jsou k dispozici na stránkách www.schema.org.
Zvolili jsme variantu co nejdéle postupovat podle dostupných specifikací a nové navrhovat jen v nutných případech. Díky tomu je specifikace mikrodat pro náš datový model z 80 % kompatibilní s mikrodaty již přijatými. Naše změny byly zaslány do konference konsorcia spravujícího projekt Schema.org a procházejí momentálně schvalovacím procesem.
Kompletní specifikaci lze najít na adrese https://github.com/OPLZZ/data-modelling. Zpracování se drží zásady snadné implementace, podobně jako v našem příkladu s adresou a mikroformáty.
Kupříkladu nabídka práce s touto podobou:
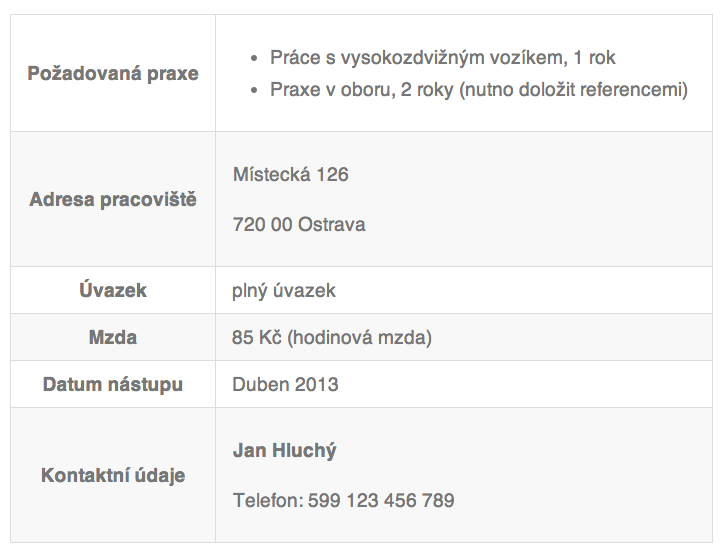
Má HTML zápis v tomto znění:
<!DOCTYPE html>
<html lang="cs" vocab="http://schema.org/"
prefix="dcterms: http://purl.org/dc/terms/">
<head>
<meta charset="utf-8">
<title>Skladník/ce - Řidič/ka VZV</title>
</head>
<body typeof="JobPosting">
<p property="title"><strong>Skladník/ce - Řidič/ka VZV</strong></p>
<div property="description">
<p>Společnost ACME s.r.o. hledá nové zaměstnance na pozici Skladník/ce - Řidič/ka VZV v lokalitě Ostrava.</p>
<p>Min. vyučení, osvědčení na vysokozdvižný vozík - podmínkou, pracovitost, bezúhonnost.</p>
</div>
<table>
<tr>
<th>Požadovaná praxe</th>
<td>
<ul>
<li rel="experienceRequirements"><span property="description">Práce s vysokozdvižným vozíkem</span>, <span property="duration" content="P1Y">1 rok</span></li>
<li rel="experienceRequirements"><span property="description">Praxe v oboru</span>, <span property="duration" content="P2Y">2 roky</span> (<span property="references" content="true">nutno doložit referencemi</span>)</li>
</ul>
</td>
</tr>
<tr rel="jobLocation">
<th>Adresa pracoviště</th>
<td>
<p property="streetAddress">Místecká 126</p>
<p>720 00 <span property="addressLocality">Ostrava</span></p>
</td>
</tr>
<tr>
<th>Úvazek</th>
<td property="employmentType">plný úvazek</td>
</tr>
<tr rel="compensation">
<th>Mzda</th>
<td><span property="value">85</span> <span property="currency" content="CZK">Kč</span> (<span property="type">hodinová mzda</span>)</td>
</tr>
<tr>
<th>Datum nástupu</th>
<td property="startDate" content="2013-04-01">Duben 2013</td>
</tr>
<tr>
<th>Kontaktní údaje</th>
<td rel="contact">
<p><strong property="name">Jan Hluchý</strong></p>
<p>Telefon: <span property="telephone" content="+420599123456789">599 123 456 789</span></p>
</td>
</tr>
</table>
<p><strong>Změněno:</strong> <span property="dcterms:modified" content="2013-03-07">7. března 2013</span></p>
</body>
</html>
Na tuto část projektu navazovalo vytvoření crawleru pro daná mikrodata a databázového serveru s API, který data dál poskytuje. Popis této části však byl již mimo záměr tohoto článku. Zájemce lze odkázat na GitHub repozitář projektu, kde jsou postupně uvolňovány všechny části projektu jako open source.
Ukázková aplikace Dáme práci
Většina výstupů, o kterých jsme hovořili doposud, nebyla primárně určena pro cílovou skupinu uchazečů. Pro tu je totiž určena HTML5 aplikace, která běží na doméně www.damepraci.cz. Vstupní data do ní tvoří směs nabídek práce získaných od inzerentů využívajících sémantické značky, nabídky práce z MPSV (to poskytuje již strukturovaná data) a dále pak data od drobných inzerentů zadaných přímo do systému.
Při designu samotné aplikace jsme museli řešit několik koncepčních problémů s ohledem na cílovou skupinu. Jak se ukázalo v našich předběžných výzkumech, existoval specifický rozdíl v konzumaci obsahu. Pro skupinu absolventů je typické využívání mobilních zařízení, hlavně mobilních telefonů. Pro skupinu 50+ zase hraje silnou roli nedůvěra vůči aplikacím požadujícím osobní údaje, k aplikacím s designem obsahujícím příliš mnoho ovládacích prvků. Také jsme si uvědomili nutnost přizpůsobit design specifickým senzomotorickým potřebám starších osob.
Již v začátku projektu jsme se rozhodli pro vytvoření HTML5 aplikace, která bude moci fungovat nejen na webu, ale také jako aplikace pro mobilní telefony (na platformě Android i iOS). Volba responsivního designu navíc zajistila, že aplikace vypadá v zásadě vždy stejně, bez ohledu na zařízení, na němž je využívána. Mění se jen počet na první pohled viditelných obrazovek.
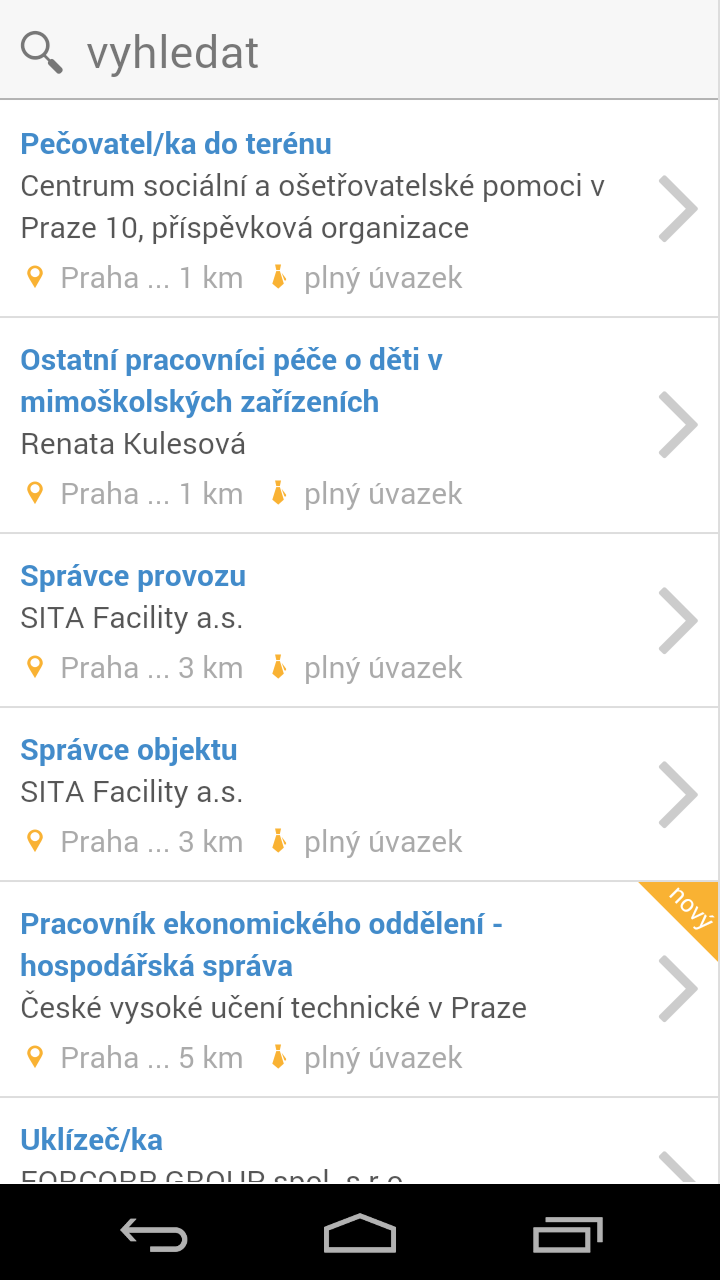
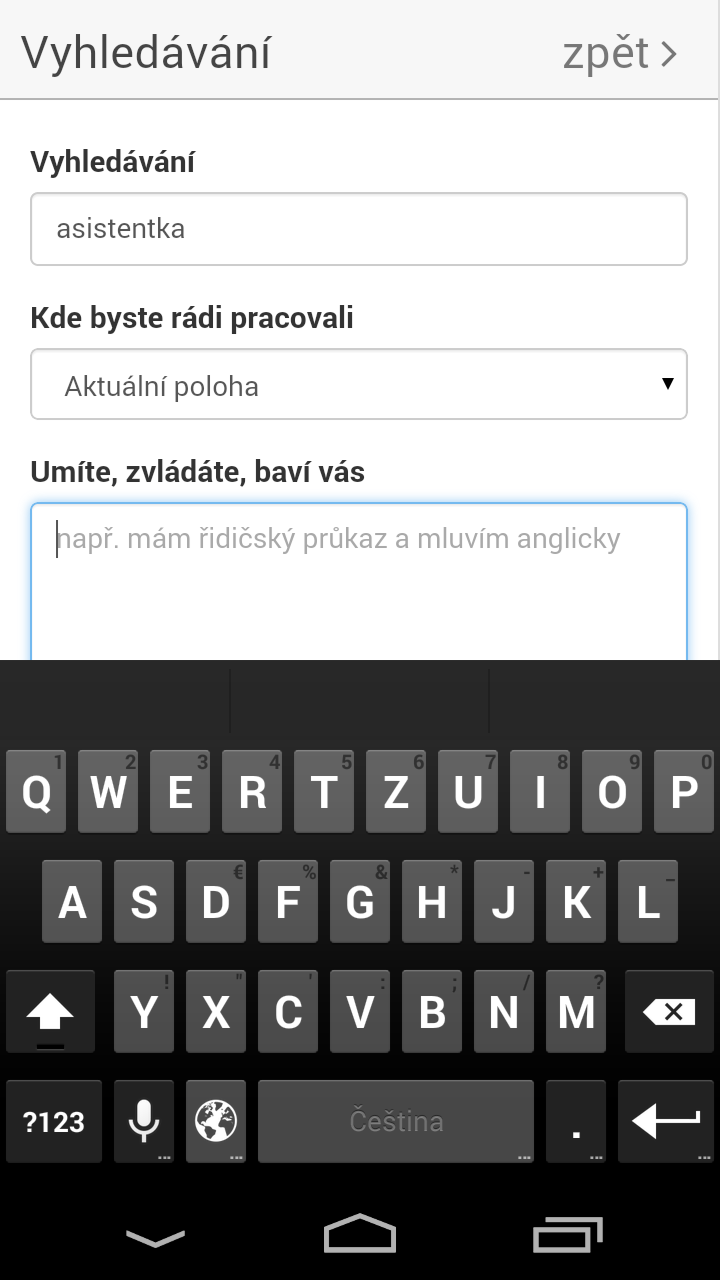
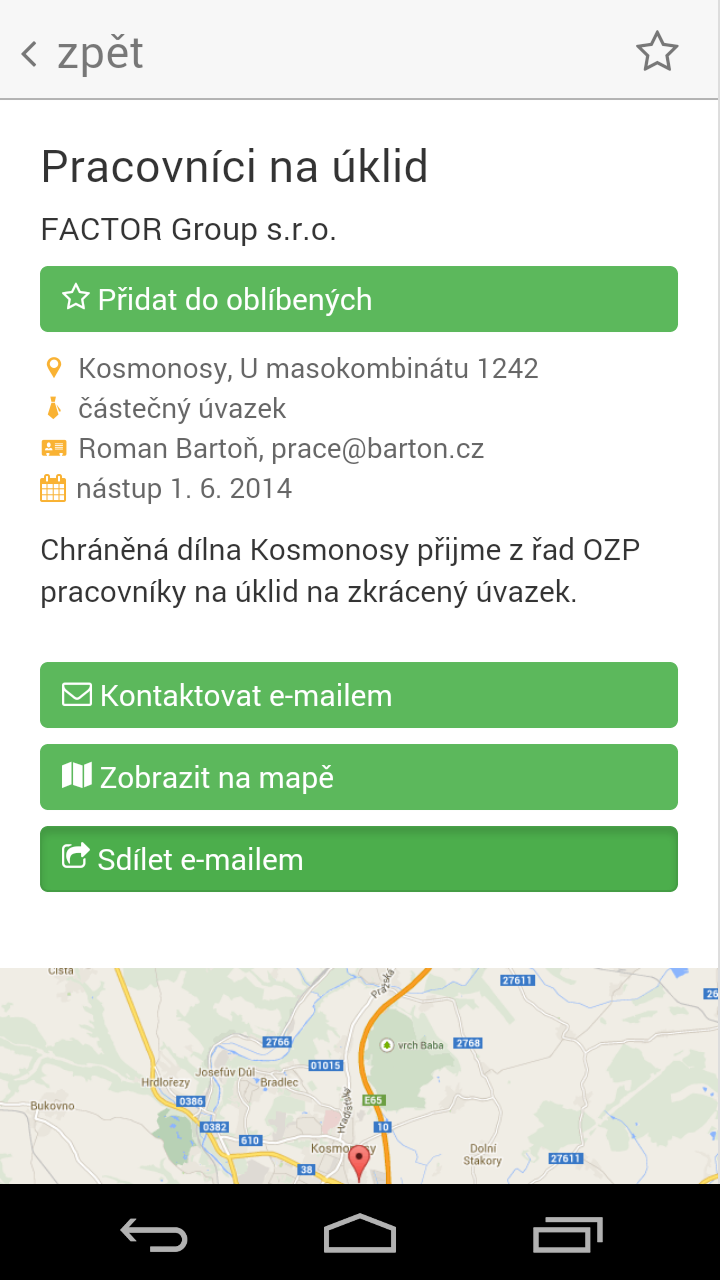
Ukázky grafického rozhraní aplikace
Pro design byly zvoleny velké dotykové plochy, které na webu vyhovují starším uživatelům a zároveň v prostředí mobilní aplikace působí přirozeně.
Pokud jde o neochotu skupiny 50+ sdílet osobní informace, rozhodli jsme, že po uživatelích služby nebudeme vyžadovat registraci. Informace, které nám o sobě napíší lidé při vyhledávání, budeme ukládat na klientské straně a vždy znovu posílat. V praxi tak na naší straně neexistuje žádná informace o identitě uživatele.
Aplikace sama se snaží zůstat co nejjednodušší. Pro uchazeče o práci je tvořena pouze třemi obrazovkami. Výpisem nabídek, detailem práce a vyhledáváním. Kromě běžných funkcí, jako je možnost ukládat oblíbené či z aplikace rovnou na mobilu vytočit číslo, jsme se zaměřili na méně běžné pojetí vyhledávání.
Základním parametrem vyhledávání byla pro nás geografická poloha, ta tvoří první komponentu z nichž se skládá pořadí výsledků. Druhou je vyhledávací dotaz v okně vyhledávání. Ten funguje jako v běžném vyhledávači. Změnou je ovšem pole “Umíte, zvládáte, baví vás” kam uživatel může o sobě napsat více informací, v nestrukturované podobě. Informace jsou následně analyzovány a obohaceny o synonyma a slouží k vylepšení nabídky práce podle předchozích dvou kritérií.
Design aplikace byl opakovaně testován nejen pomocí klasického uživatelského testování, ale také během samotných workshopů se zástupci všech cílových skupin.
Další výhledy
Určitou inspirací pro náš projekt byly hyperlokální nabídky mikroprací známé z USA. Ty v podstatě umožňují zadávat drobné, sousedské práce ve větších městech. Mezi takové práce patří kupříkladu odvoz nákupu, sklizení ovoce či větší úklid v domě.
Služby jako TaskRabbit nabídkou mikroprací pomáhají nejen lidem bez práce alespoň k nějakému výdělku, ale také jim pomáhají udržovat sociální kontakt, což je pro dlouhodobě nezaměstnané nesmírně důležité. Bohužel česká právní úprava není v tomto ohledu příliš jednoznačná, a tak se lidé do mikroprací příliš nepouštějí, aby se nedopustili neoprávněného podnikání. Navíc je tento druh příjmu limitován maximální částkou 30.000 Kč ročně.
Z dlouhodobého pohledu je ale zřejmě tato situace neudržitelná a je velmi pravděpodobné, že dojde k uvolnění trhu v této oblasti i u nás. Aplikace Dáme práci s takovou variantou počítá a je na ni připravena.
Závěr
První výsledky naznačují, že využití sémantických technologií pro specifickou oblast přináší pozitivní výsledky. Nejen v oblasti přírůstku zpracovaných dat, ale především v oblasti zlepšení výsledků vyhledávání. Ukazuje se také, že lepší výsledky přináší kombinování sémantického přístupu s přístupem statistickým, což není překvapivé a odpovídá to zkušenostem z jiných oblastí.
Pro šetření spokojenosti s rozhraním aplikace jsme mj. využili adaptovanou metodu Microsoft reaction cards. Cílové skupiny se shodly v konstatování, že hlavním kladem aplikace je jednoduchost v designu, snadnost vyhledávání a intuitivní možnosti práce s inzerátem. Pilotní aplikace má po několika měsících stovky unikátních návštěvníků denně dle Google Analytics. Během první tří měsíců návštěvnost plynule rostla a zdá se, že si aplikace našla své uživatele.

Projekt č. CZ.1.04/5.1.01/77.00440 je financován z Evropského sociálního fondu prostřednictvím Operačního programu Lidské zdroje a zaměstnanost a ze státního rozpočtu ČR
- Viz jeho studie The Unreasonable Effectiveness of Data url: http://www.datascienceassn.org/sites/default/files/Unreasonable%20Effectiveness%20of%20Data.pdf